
これまでmatplotlibの記事などを通して、グラフを使ってデータを分かりやすく表現する方法を学んできました。
「Pythonを使って数学の視覚化をする」シリーズの続きとして、今回はゲーム開発やデータサイエンスの基礎となる「ベクトル」に挑戦します。
数学の教科書で見かけるベクトルも、プログラミングを使って実際に矢印を描画して動かしてみると、分かりやすくなります。
ベクトルとは
「ベクトル」とは、一言で表すと「大きさと向きを持った量」のことです。例えば、日常の会話で「北東に向かって時速50kmで進む車」といった場合、「北東」という向きと、「時速50km」という大きさ(スピード)の両方を持っているので、これはベクトルとして表現できます。ゲームの世界でも、「キャラクターが右斜め上にジャンプする」といった動きはすべてベクトルで計算されています。
一方、「今日の気温は20度だ」とか「体重が50kgある」といった数値は、大きさはありますが、向きは持っていません。このような量のことは「スカラー」と呼んで区別します。
Pythonで平面(2D)のベクトルを表現する時は、「横(\(x\))にどれくらい進み、縦(\(y\))にどれくらい進むか」という2つの数字のペアを使います。例えば\(x\)方向に3、\(y\)方向に4進むベクトルなら、要素として3と4を持ったデータとして扱います。
では、実際にやってみましょう。
Google Colaboratory (Colab) を開いて新しいノートブックを作成し、原点から伸びるベクトルの矢印を描画するプログラムを書いてみます。矢印を描くには、matplotlib の中にある quiver(クイーバー:矢筒という意味)という機能を使います。
import matplotlib.pyplot as plt
# ベクトルの成分を用意する(右に3、上に4進む矢印)
vec_x = 3
vec_y = 4
# グラフを描くための枠組みの準備
fig, ax = plt.subplots()
# quiverを使って原点(0, 0)から伸びる矢印を描く
ax.quiver(0, 0, vec_x, vec_y, angles="xy", scale_units="xy", scale=1, color="blue")
# グラフの表示範囲を固定する
ax.set_xlim(-1, 5)
ax.set_ylim(-1, 5)
# グラフの縦横の比率を同じにする(矢印が歪まないようにする)
ax.set_aspect("equal")
# グラフにグリッド(目盛り線)を表示する
plt.grid(True)
# グラフを描画する
plt.show()とセルに入力して実行してみましょう。すると結果は
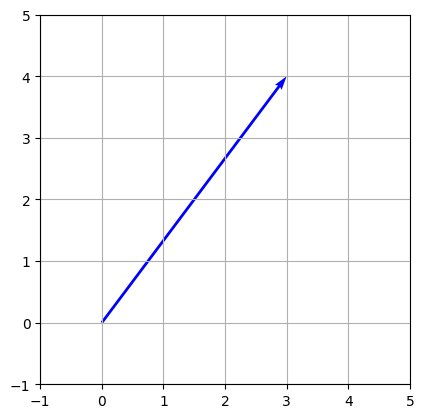
のように表示されます。
プログラムの解説(単一のベクトルの描画)
- 成分の準備(4~5行目): 変数
vec_xとvec_yに、それぞれ横方向と縦方向の移動量を代入しています。 - グラフの枠組みの準備(8行目):
fig, ax = plt.subplots()で、グラフ描画の準備をします。 - 矢印の描画(11行目):
ax.quiver(0, 0, vec_x, vec_y)と記述することで、グラフの座標(0, 0)をスタート地点として、そこから\(x\)方向に3、\(y\)方向に4進む矢印を描画しています。後ろに書かれているangles="xy", scale_units="xy", scale=1という部分は、矢印の長さや角度をグラフの目盛りと正確に連動させるためのものです。 - 範囲と比率の調整(14~18行目):
set_xlimとset_ylimでグラフの表示範囲を整え、set_aspect("equal")で画面の縦横比1:1の正方形に固定しています。
ベクトルの足し算(合成)
ベクトルが「向き」と「大きさ」を持っていることが分かったところで、次は複数のベクトルを合わせる「足し算(合成)」を考えてみましょう。
複数の力が同時に働いた時、最終的にどの方向へどれくらいの力で進むのかを求めるのがベクトルの足し算です。ここでは分かりやすく、2つの力が加わった場合を例に考えてみましょう。例えば、「右に3、上に1進む力(ベクトル\(\vec{a}\))」と「左に1、上に3進む力(ベクトル\(\vec{b}\))」が同時に加わったとします。これを視覚的に表すには、「1つ目の矢印の先端から、2つ目の矢印をスタートさせる」ことで、最終的な到達点を見つけることができます。
では、実際にやってみましょう。
Colabの新しいセルに、2つのベクトルとその合計(合成ベクトル)を描画するプログラムを書いてみます。
import matplotlib.pyplot as plt
# ベクトルaの成分(右に3、上に1)
a_x = 3
a_y = 1
# ベクトルbの成分(左に1、上に3)
b_x = -1
b_y = 3
# 合成ベクトルcの成分を計算する(aとbの足し算)
c_x = a_x + b_x
c_y = a_y + b_y
# グラフを描画するための準備
fig, ax = plt.subplots()
# ベクトルaを描く(原点からスタート、色は赤)
ax.quiver(0, 0, a_x, a_y, angles="xy", scale_units="xy", scale=1, color="red", label="Vector a")
# ベクトルbを描く(ベクトルaの先端からスタート、色は青)
ax.quiver(a_x, a_y, b_x, b_y, angles="xy", scale_units="xy", scale=1, color="blue", label="Vector b")
# 合成ベクトルcを描く(原点から最終地点まで、色は紫)
ax.quiver(0, 0, c_x, c_y, angles="xy", scale_units="xy", scale=1, color="purple", label="Vector c (a+b)")
# グラフの表示範囲を整える
ax.set_xlim(-2, 4)
ax.set_ylim(-1, 5)
ax.set_aspect("equal")
# グリッドを表示する
plt.grid(True)
# loc="upper left" を指定して、凡例(ラベル)を「左上」に配置する(ベクトルとの重なりを防ぐため)
plt.legend(loc="upper left")
# グラフを描画する
plt.show()とセルに入力して実行してみましょう。すると結果は
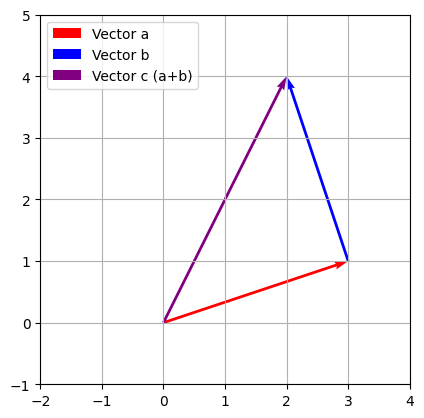
のように表示されます。
プログラムの解説(合成ベクトルの描画)
- 足し算の計算(12~13行目): 変数
c_xとc_yに、ベクトル\(\vec{a}\)と\(\vec{b}\)の成分同士を足し合わせた結果を代入しています。 - 継ぎ足しの描画(21行目): 2つ目のベクトル\(\vec{b}\)を描画する際、
ax.quiver(a_x, a_y, b_x, b_y)と記述しています。スタート地点を原点の(0, 0) ではなく、ベクトル\(\vec{a}\)の先端である(a_x, a_y)に変更することで、「矢印の先端から次の矢印が始まる」という動きを表現しています。 - 合成ベクトルの描画(24行目): 原点(0,0)から、計算して求めた最終地点(c_x,c_y)に紫色の矢印を描いています。
- 凡例の位置調整(34行目):
plt.legend(loc="upper left")と記述することで、凡例(ラベル)の表示位置を左上に指定しています。何も指定しないと自動で空いている場所に配置されますが、このように指定することでグラフの線と被るのを防ぐことができます。
[補足] データサイエンスにおけるベクトルの活用
記事の冒頭で「データサイエンスの基礎となる」と触れましたが、ここでは視覚化(グラフ)からは少し離れて、実際にデータサイエンスやAIの世界でベクトルがどのように使われているかを補足として解説します。
なぜデータサイエンスでベクトルを使うのか
コンピュータは、私たちが普段目にする「文章」や「画像」、「ユーザーの好み」といったデータをそのままでは処理できません。内部で効率よく計算や分析を行うために、それらの情報を「数値」に置き換えて扱う仕組みになっているからです。
そこで、あらゆるデータを「数字のリスト(=ベクトル)」に変換します。分析の対象となる個々の要素(年齢や身長など)を「特徴量(とくちょうりょう)」と呼び、それらを並べてリスト化したものを「特徴ベクトル(Feature vector)」と呼びます。
例えば、ある人のプロフィールを考えてみましょう。
- 年齢:30歳
- 身長:170cm
- 体重:65kg
これをベクトルにすると[30, 170, 65]というデータになります。
このようにデータをベクトル(数値のリスト)化することで、データ同士を数学的に計算したり、比較したりできるようになります。
NumPyとは
これからの解説や実際のコードで、これまで使ってきた標準の「リスト([])」ではなく、「NumPy(ナムパイ)」という外部ライブラリを使用します。
NumPyはベクトルや行列といった大量の数値データを、高速に計算するためのライブラリです。
Python標準のリストでベクトルの足し算や掛け算を行おうとすると、複雑なfor文を書かなければならず、実行速度も遅くなってしまいます。しかし、NumPyを使えば数式を短いコードで書くことができ、さらに計算が高速で終わります。
データの類似度を測る「コサイン類似度」
データをベクトル化すると、データ同士がどれくらい似ているかを数学的に計算して比較できるようになります。
その比較の際に使われる代表的な計算方法が「コサイン類似度(Cosine Similarity)」です。
コサイン類似度は、ベクトルの「長さ」を無視して、「2つのベクトルの間の角度(向き)」だけを比較する計算方法です。
数学で習うベクトルの内積と\(\cos\)(コサイン)の性質を利用しています。
数学で習うベクトルの内積の公式は以下のようになります。
$$
\vec{a} \cdot \vec{b} = |\vec{a}| |\vec{b}| \cos(\theta)
$$
この式を \(\cos(\theta)\)について解き直したものが、コサイン類似度の数式です。
$$
\text{Cosine Similarity} = \cos(\theta) = \frac{\vec{a} \cdot \vec{b}}{|\vec{a}| |\vec{b}|}
$$
- \(\vec{a} \cdot \vec{b}\)は2つのベクトルの「内積」
- \(|\vec{a}| \)と \(|\vec{b}|\) はそれぞれのベクトルの「大きさ(長さ)」
- \(\theta\)は2つのベクトルの間の「角度」
\(\cos\)(コサイン)には、角度によって1から-1の間を変動するという性質があります。これを利用して、ベクトルの向きの近さを判定します。
- 角度が0度(全く同じ向き): \(\cos(0^\circ) = 1\) となり、「類似度1.0 (100%似ている)」と判定されます。
- 角度が90度(全く関係ない向き): \(\cos(90^\circ) = 0\) となり、「類似度0 (全く似ていない)」と判定されます。
- 角度が180度(全く逆の向き): \(\cos(180^\circ) = -1\) となり、「類似度-1.0 (完全に逆)」と判定されます。
なぜ「距離」ではなく「コサイン類似度」を使うのか
似ているデータを探す際、なぜ単純なグラフ上の距離ではなく、コサイン類似度という計算方法を使うのでしょうか。
例えば、次のような二人がいたとします。
- ユーザーA: 本に1000円、家電に2000円使った。
- ユーザーB: 本に10000円、家電に20000円使った。
使った金額の合計(規模)は違いますが、どちらも「家電に本の2倍の金額を使っている」というお金の使い方の割合(傾向)は一致しています。
もしこれを単なるグラフ上の「2点間の距離」で計算してしまうと、金額のスケールが離れすぎているため「この二人は全然似ていない」と判定されてしまいます。しかし、これらを原点から伸びる「ベクトル」として描いてみると、矢印の長さは違っても、矢印の向いている方向(角度)は同じになります。
データの「規模(買う量)」ではなく「傾向(好みのジャンル)」を重視して比較したい場合に、このコサイン類似度が活躍します。
ノルムとシグマ(\(\Sigma\))を使った数式表現
データサイエンスの専門書や論文を読むと、数式がより数学的に厳密な「ノルム」や「シグマ(\(\Sigma\))」を使った形で書かれていることがよくあります。まずはこれらの記号の意味を理解してみましょう。
- ノルム(Norm)とは: 先ほどの式で\(|\vec{a}|\)と書いていた「ベクトルの大きさ(長さ)」のことを、ノルムと呼びます。二重の縦線を使って\(|\vec{a}|\)と表記されます。
- シグマ(\(\Sigma\))とは: \(\Sigma\) (シグマ)は、「たくさんの数字を順番に足し合わせる(合計する)」という指示を表す数学記号です。
一見すると難しく見える数式ですが、これはプログラミングの「繰り返し処理(for文)」を使えば簡単に表現できます。
シグマやノルムの動きをPythonで表してみる
数学の記号が裏側でどのような計算を行っているのか、あえてNumPyなどの便利なライブラリを使わずに、Pythonの基本文法(for文)だけで内積とノルムを計算するコードを書いてみましょう。
Colabの新しいセルに以下のコードを入力して実行してみてください。
import math
# 2つのベクトル(リスト)を用意する
vec_a = [3, 4]
vec_b = [1, 2]
# 1.内積(シグマ)の計算
# 分子:Σ(a_i * b_i) に対応
dot_product = 0
for i in range(len(vec_a)):
# 同じ場所の要素を掛けて足し合わせる
dot_product += vec_a[i] * vec_b[i]
# 2.ノルム(長さ)の計算
# 分母: √(Σ(a_i^2))に対応
norm_a_squared = 0
for val in vec_a:
# 要素を2乗して足し合わせる
norm_a_squared += val ** 2
# 最後にルートを被せる
norm_a = math.sqrt(norm_a_squared)
print(f"for文で計算した内積: {dot_product}")
print(f"for文で計算したノルム: {norm_a}")とセルに入力して実行してみましょう。すると結果は
for文で計算した内積: 11
for文で計算したノルム: 5.0
のように表示されます。難しそうな数学の記号も、プログラムで書くと、for文を使ったシンプルな足し算の繰り返しであることが実感できると思います。
数式とNumPyの対応関係
上で書いたようなfor文による地道な計算を、自分で書かなくても1行で、かつ高速に計算してくれるのが「NumPy」というライブラリです。実際に、先ほどのfor文と全く同じ計算をNumPyを使って書いてみましょう。
Colabの新しいセルに以下のコードを入力して実行してみてください。
import numpy as np
# NumPyのベクトル(配列)を用意する
vec_a_np = np.array([3, 4])
vec_b_np = np.array([1, 2])
# 1.内積(シグマ)の計算
dot_product_np = np.dot(vec_a_np, vec_b_np)
# 2.ノルム(長さ)の計算
norm_a_np = np.linalg.norm(vec_a_np)
print(f"NumPyで計算した内積: {dot_product_np}")
print(f"NumPyで計算したノルム: {norm_a_np}")とセルに入力して実行してみましょう。
すると結果は
NumPyで計算した内積: 11
NumPyで計算したノルム: 5.0
のように表示されます。for文で書いた時と同じ結果が、よりシンプルなコードで出力されましたね。
成分を使った数式
ベクトル\(\vec{a}\)と\(\vec{b}\)がそれぞれn個の要素(例えば\(a_1, a_2, \dots, a_n\))を持っている場合、内積やノルムをΣを使って展開すると、コサイン類似度の式は次のように表現されます。
$$
\text{Cosine Similarity} = \frac{\vec{a} \cdot \vec{b}}{\|\vec{a}\| \|\vec{b}\|} =
\frac{\sum_{i=1}^{n} a_i b_i}{\sqrt{\sum_{i=1}^{n} a_i^2} \sqrt{\sum_{i=1}^{n} b_i^2}}
$$
- 分子(上段): \(\sum_{i=1}^{n} a_i b_i\) は、「ベクトルの同じ場所(\(i\)番目)にある要素同士を掛け算して、すべて足し合わせる」という内積の計算手順を表します(コードの
np.dot(vec_a_np, vec_b_np)に対応します)。 - 分母(下段): \(\sqrt{\sum_{i=1}^{n} a_i^2}\)は、「それぞれの要素を2乗してすべて足し合わせ、最後にルート(\(\sqrt{}\))を被せる」というノルム(長さ)の計算手順を表します(コードの
np.linalg.norm(vec_a_np)に対応します)。
一見すると難しく見える数式ですが、実はPythonのプログラムにやらせている計算手順を、数学の記号を使って正確に記述しているだけなのです。
実用例
このコサイン類似度は、ショッピングサイトや動画配信サービスでよく見かける「あなたへのおすすめ(レコメンドシステム)」機能で使われています。
ユーザーの購買履歴や好みをベクトルに変換し、コサイン類似度を使って比較することで、似ているユーザーや似ている商品を見つけ出しているのです。
Pythonを使ったコサイン類似度の計算例
それでは、NumPyを使ってユーザー同士の「似ている度合い」をベクトルで計算してみましょう。
Colabの新しいセルに、以下のコードを入力して実行してみてください。
import numpy as np
# 3人のユーザーの購買データを用意する
# 例:[書籍, 家電, 食品, 衣類]の購入金額(円)
user_a = np.array([5000, 20000, 3000, 0]) # 本と家電を買っている
user_b = np.array([4000, 15000, 2000, 1000]) # ユーザーaと似ている
user_c = np.array([0, 0, 5000, 30000]) # 衣類を買っている (ユーザーaとは似ていない)
# コサイン類似度(ベクトルの向きの近さ)を計算する関数
def cosine_similarity(v1,v2):
# 2つのベクトルの内積(要素ごとの掛け算の合計)を計算する
dot_product = np.dot(v1, v2)
# それぞれのベクトルの大きさ(長さ)を計算する
norm_v1 = np.linalg.norm(v1)
norm_v2 = np.linalg.norm(v2)
# 内積を、大きさの掛け算で割ることで、コサイン類似度を求める
# 完全に同じ向きなら1.0に近づき、全く関係ない向きなら0.0に近づく
return dot_product / (norm_v1 * norm_v2)
# 類似度を計算して表示する
sim_ab = cosine_similarity(user_a, user_b)
sim_ac = cosine_similarity(user_a, user_c)
print(f"ユーザーAとユーザーBの類似度: {sim_ab:.3f}")
print(f"ユーザーAとユーザーCの類似度: {sim_ac:.3f}")とセルに入力して実行してみましょう。すると結果は
ユーザーAとユーザーBの類似度: 0.998
ユーザーAとユーザーCの類似度: 0.024
のように表示されます。
プログラムの解説(コサイン類似度の計算)
- ライブラリの読み込み(1行目):
import numpy as npと記述して、数値計算を高速に行うためのライブラリ「NumPy」を、プログラム内でnpという短い名前で使えるように準備しています。 - NumPyのベクトルの作成(5~7行目):
np.array([...])を使って、Python標準のリストを、高速な数学計算ができるNumPy専用のベクトルデータに変換しています。 - 自作関数の定義(10行目):
def cosine_similarity(v1, v2):と記述し、2つのベクトル(v1とv2)を受け取ってコサイン類似度を計算するための、自分独自の関数(命令)を作成しています。これで、計算式を何度も書かずに済むようになります。 - 内積と大きさの計算(13~17行目): 関数の中で
np.dot()で内積を、np.linalg.norm()でベクトルのノルム(大きさ)を計算しています。これらのベクトルの角度(コサイン類似度)を求めるための数学の公式通りにNumPyの機能を呼び出しています。 - 類似度の判定(24~28行目): 結果を見ると、ユーザーAとBの類似度は0.998と、最大値である1.0に非常に近い数値になり、「買う量は違っても、購買傾向がとても似ている」と判定されました。一方でAとCの類似度は0.024となり、「似ていない」と判定されています。
このようにベクトルの計算を使って、「ユーザーAとBは似ているから、Bが買った商品をAにもおすすめしよう」という処理を行っています。
scikit-learnを使ってさらに短く
先ほど自作したようなコサイン類似度の計算を、さらに簡単かつ高速に行うためのライブラリ「scikit-learn(サイキットラーン)」がよく使われています。
scikit-learnとは
scikit-learnは、Pythonで機械学習やデータ分析を行うための、代表的なライブラリです。「機械学習」と聞くとAIを作るための難しいツールのように思えるかもしれませんが、今回のような「データ同士の類似度を計算する」「データを綺麗に分類する」といった、データサイエンスに必要な便利機能が詰め込まれています。
先ほど、NumPyを使って内積やノルムを求める計算式(def cosine_similarity の部分)を自分で作成しました。しかし、実際は、このような汎用的な計算式を自分たちで一から書くことはほとんどありません。複雑な数式を自作しなくても、あらかじめ用意された機能(関数)を呼び出すことで計算ができるからです。また、コードが短ければ短いほど、エラー(バグ)が発生する確率も減ります。
これからscikit-learnの cosine_similarity という機能を使いますが、コードを書く前に一つ注意点があります。
scikit-learnの多くの機能は、「何千、何万という複数のユーザーのデータを、まとめて一気に計算する」ことを前提に作られています。そのため、一人分のデータであっても[5000, 20000, 3000, 0] というただのリスト(1次元)ではなく、リストをさらにリストで囲んだ[[5000, 20000, 3000, 0]] という形(2次元の配列・行列)にして渡さなければならないというルールがあります。つまずきやすいポイントなので覚えておきましょう。
実際にscikit-learnを使って、先ほどと全く同じ計算を行ってみましょう。Colabには最初からこのライブラリが入っているので、すぐに試すことができます。
from sklearn.metrics.pairwise import cosine_similarity
# scikit-learnの仕様に合わせて、データを「2次元(リストのリスト)」の形で用意する
user_a_2d = [[5000, 20000, 3000, 0]] # 本と家電を買っている
user_b_2d = [[4000, 15000, 2000, 1000]] # ユーザーaと似ている
user_c_2d = [[0, 0, 5000, 30000]] # 衣類を買っている (ユーザーaとは似ていない)
# 用意された関数にデータを渡して計算できる
sim_ab_sklearn = cosine_similarity(user_a_2d, user_b_2d)
sim_ac_sklearn = cosine_similarity(user_a_2d, user_c_2d)
# 結果も2次元の形で返ってくるため、[0][0]を指定して目的の数値だけを取り出す
print(f"scikit-learnでのAとBの類似度: {sim_ab_sklearn[0][0]:.3f}")
print(f"scikit-learnでのAとCの類似度: {sim_ac_sklearn[0][0]:.3f}")これを実行すると、先ほど自作した計算結果(0.998と0.024)と全く同じ結果が得られます。
このように、既に存在する便利なライブラリ(NumPyやscikit-learnなど)を組み合わせて、コードをできるだけ短くシンプルに書きあげるのが、基本スタイルです。
まとめ
今回は、プログラミングを使って「ベクトル」を視覚化する方法や、データサイエンスにおける活用方法について解説しました。
- ベクトルの概念と描画: 「大きさと向き」を持った量。
matplotlibのquiver関数を使って矢印として座標上に描き、ax.set_aspect("equal")で歪みを防ぐ。 - データサイエンスでの活用(特徴ベクトル): あらゆるデータ(文章や画像、人の好みなど)を数値のリスト(ベクトル)に変換することで、コンピュータが数学的に比較・計算したり、AIに学習させたりできるようになる。
- コサイン類似度: データの「規模(長さ)」ではなく、「傾向(角度)」を比較するための計算方法。おすすめ機能などで活躍する。
- 便利なライブラリ: NumPyやscikit-learnなどを使えば、複雑な計算を短いコードで高速に実行できる。
ベクトルはゲームプログラミングやデータサイエンスで必要になる知識です。ぜひ色々な数値を入れて、矢印の動きや類似度を実験してみてください。

今回はこれで終了です。
今回のサンプルを用意したので、もし必要な場合は上の「Open in Colab」と書いてあるボタンをクリックしてください。なおそのままだと編集不可なので編集をしたい場合は「ドライブにコピー」をクリックしてコピーしてください。